
Striving for self-driving on Model T
The new wave of AI coding copilots presents the biggest boost to developer productivity since the IDE, but our expectations might be too high for current models.

The code copilot landscape has grown a lot in the last 2 years. The number of players that launched is a clear testament that software development is one of the fields that will gain most from LLMs:
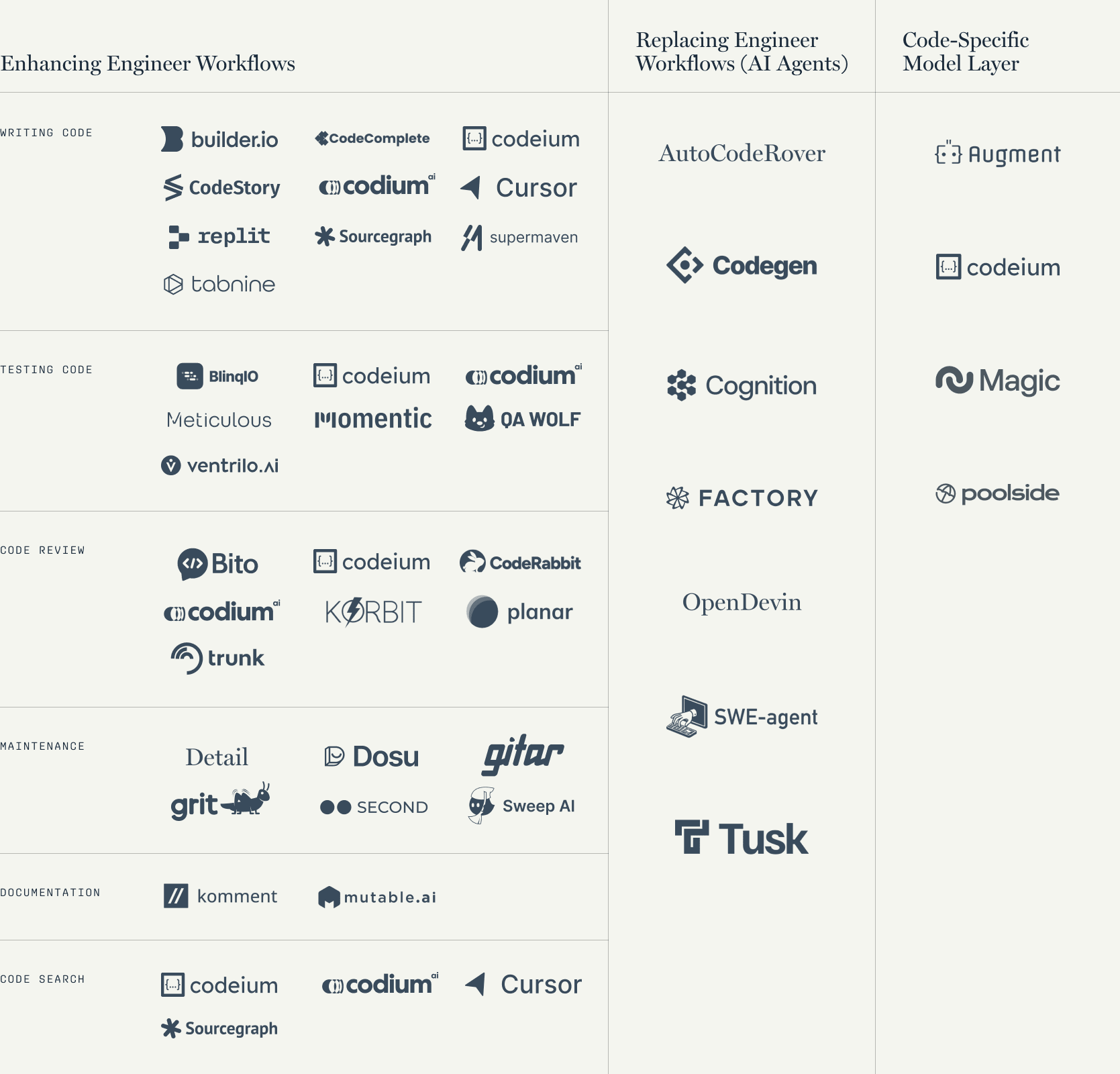
As a developer, this is great, you can try a new tool every month – each one better than the last.
As a startup that is building something in this space, it is also a great sign. It is one of the fields where we’re still discovering what works and that comes with a great opportunity to leave a mark.
New LLM models have surprised everyone with their ability to understand and generate code, allowing for developers to move faster. Using a coding assistant feels like driving a Model T when everyone else is in a stagecoach.
Even if the current critiques are partly right on their limitations, same as with the first mass-produced car from Ford, they will only be temporarily right.
The current road
Out of all the abilities that new copilots are trying to implement (autocomplete, test generation, chat with a code base, etc), the one that gets the most press is the fully autonomous AI software developer. The kind built by Cognition, OpenHands, Aider, etc.
The big problem I’m seeing is that the models just aren’t there yet.
As capable as they are, they can’t run independently for a long time without going astray. That is an important feature for an agent to work on a problem for a couple minutes / hours.
Another problem is finding the right context for each step of the task.
The currently used RAG techniques seem to get us incrementally closer to that “self-driving“ dream but that technology isn’t there yet either.
If 2024 tech were to be put on a Model T car, I bet it could work, but the problem is that we don’t have “2024 tech” when it comes to building the right context for programming tasks. Current techniques are coming from classic search. We are still very early on.
A better approach would be to get this great new product, Model T, and start adding features that makes it more powerful, safer and comfortable to use now:
automatic gearbox (in editor auto-complete)
seat belts (automatic test generation)
comfy leather seats (always up-to-date code documentation)
With these features, it would be possible to improve an already great product and if another model comes along, simply transfer them over.
Expectations are that current models will improve enough in the next 2 years to guarantee this type of agentic behavior.
How to get there
If the goal is to get to fully autonomous agents, there are multiple improvements that are needed to get there. These include everything from code base understanding (through embeddings, ASTs, etc.) to understanding a project’s dependencies, all of which powerful on their own and can also offer value to developers individually.
All of these techniques are mostly used at inference time to improve the context of a model. The biggest critique that I hear is that they will become irrelevant once the models become big enough.
Leaving aside the rumors that we are hitting a performance wall (which are far from true), as these models continue to improve, the right strategy is to use current RAG techniques to get as close as possible to where the model should be, and when the model finally gets there, just deprecate the parts that are obsolete.
In this way, we can juice a lot of performance from current general models without waiting for them to get good enough at working with infinite context.
Another advantage for this system is that it might not make sense to use enormous models because of inference cost.
We can use 2.000.000 context models today and put a whole code base in them but the cost is huge (around 5$ per request, for gemini) and the quality is not great.
The big problem with “put everything in context” is what does everything mean?
Does it mean the whole code base?
What about all of its dependencies?
What about all the documentation for typescript?
How do we know what the model knows? What if it doesn’t know about the latest version of React? Developers would still need a basic RAG pipeline to create a relevant context. This is slippery slope where you still need to fill in the gaps of the model.
Not to mention that zero-shot learning is a lot cheaper than pre-training.
What should we focus on
The real differentiator will be the interface and context-building.
As the big labs focus on improving models, I think most of the value will be in building the right context at inference time and offering the right UI for the task at hand.
Another great article on this subject is Ivan from Daytona’s post.
Chat has become the go-to interface, but AI code pilots are far from their final form. There will most likely be a number of interfaces that become available, each suited to different tasks. The development flow requires multiple steps that are pretty different from each other (issue understanding, code review, deployment, etc.) and separate interfaces are needed. But, I think most will be based on the chat interface because the linearity of a chat conversation is really powerful.
Context building is the next big frontier to get great ROI until models catch up. Finding the right piece of code, or the right library for a task, is a very hard problem, but also an old one. There is a field in software engineering that’s been focusing on this for the past 80 years: information retrieval.
So even if we are “stuck” with a Model T right now, we can put comfy leather chairs on it, an automatic gearbox, an ABS and even some 22”. Additions like these can improve the driving experience ten fold until we get the next version of car chassis.